








Uma introdução aplicada a redes adversárias generativas

GANs, um dos maiores avanços na aprendizagem sem supervisão nos últimos anos, nos aproximará um pouco da inteligência artificial geral.
A maioria dos sucessos de inteligência artificial (IA) nos últimos anos ocorreu em problemas definidos de forma restrita, como classificação de imagem, visão por computador, reconhecimento de fala e tradução automática, com a disponibilidade de grandes conjuntos de dados, computadores incrivelmente poderosos e algoritmos de aprendizagem supervisionados .
No entanto, a inteligência artificial geral – o Santo Graal da pesquisa AI – continua a ser um objetivo distante, que levará décadas para alcançar. Muitos na comunidade da IA acreditam que grandes avanços na aprendizagem sem supervisão – a capacidade de aprender com dados sem rótulos – são a chave da inteligência artificial geral.
Quais são as redes contraditórias generativas?
Um grande avanço na aprendizagem sem supervisão foi o advento das redes adversárias generativas (GANs), introduzidas por Ian Goodfellow e seus colegas pesquisadores da Universidade de Montreal em 2014. Os GANs têm muitas aplicações; Por exemplo, podemos usar GANs para criar dados sintéticos quase realistas, como imagens e fala, ou realizar detecção de anomalia.
Nos GANs, temos duas redes neurais. Uma rede – conhecida como “gerador” – gera dados com base em uma distribuição de dados modelo que criou usando amostras de dados reais que recebeu. A outra rede – conhecida como “discriminador” – difunde os dados criados pelo gerador e os dados da distribuição de dados verdadeira.
Como uma analogia simples, o gerador é o falsificador, e o discriminador é a polícia tentando identificar a falsificação. As duas redes estão bloqueadas em um jogo de soma zero. O gerador está tentando enganar o discriminador para pensar que os dados sintéticos provêm da distribuição de dados verdadeira, e o discriminador está tentando chamar os dados sintéticos como falsos.
Os GANs são algoritmos de aprendizagem sem supervisão porque o gerador pode aprender a estrutura subjacente da distribuição de dados verdadeira mesmo quando não há rótulos. Aprende a estrutura subjacente usando uma série de parâmetros significativamente menores do que a quantidade de dados em que treinou. Essa restrição força o gerador a capturar eficientemente os aspectos mais salientes da distribuição de dados verdadeira.
Isso é semelhante ao aprendizado de representação que ocorre no aprendizado profundo. Cada camada escondida na rede neutra de um gerador captura uma representação dos dados subjacentes – começando de forma muito simples – e as camadas subseqüentes retomam representações mais complicadas ao construir as camadas precedentes mais simples. Usando todas essas camadas em conjunto, o gerador descobre a estrutura subjacente dos dados e, usando o que aprendeu, o gerador tenta criar dados sintéticos que são quase idênticos à distribuição de dados verdadeira. Se o gerador tiver capturado a essência da distribuição de dados verdadeira, os dados sintéticos aparecerão reais.
Aplicações do mundo real de GANs
Para aplicações do mundo real, tanto o gerador quanto o discriminador são valiosos. Se o objetivo é gerar muitos novos exemplos de treinamento para ajudar a complementar os dados de treinamento existentes – por exemplo, para melhorar a precisão em uma tarefa de reconhecimento de imagem – podemos usar o gerador para criar muitos dados sintéticos, adicionar os novos dados sintéticos a os dados de treinamento originais e, em seguida, execute um modelo de aprendizagem de máquinas supervisionado no agora muito maior conjunto de dados.
Se o objetivo é identificar anomalias – por exemplo, para detectar fraudes, piratarias ou outros comportamentos suspeitos – podemos usar o discriminador para marcar cada instância nos dados reais. As instâncias em que o discriminador classifica como “provavelmente sintético” serão as instâncias mais anômalas e também as que são mais propensas a representar comportamentos maliciosos.
Uma distribuição simples de dados unidimensional
Consideremos um exemplo simples: suponha que possamos uma verdadeira distribuição de dados de alturas para homens nos Estados Unidos, que normalmente é distribuída (Figura 1) com uma média de 69 polegadas e um desvio padrão de 3 polegadas.
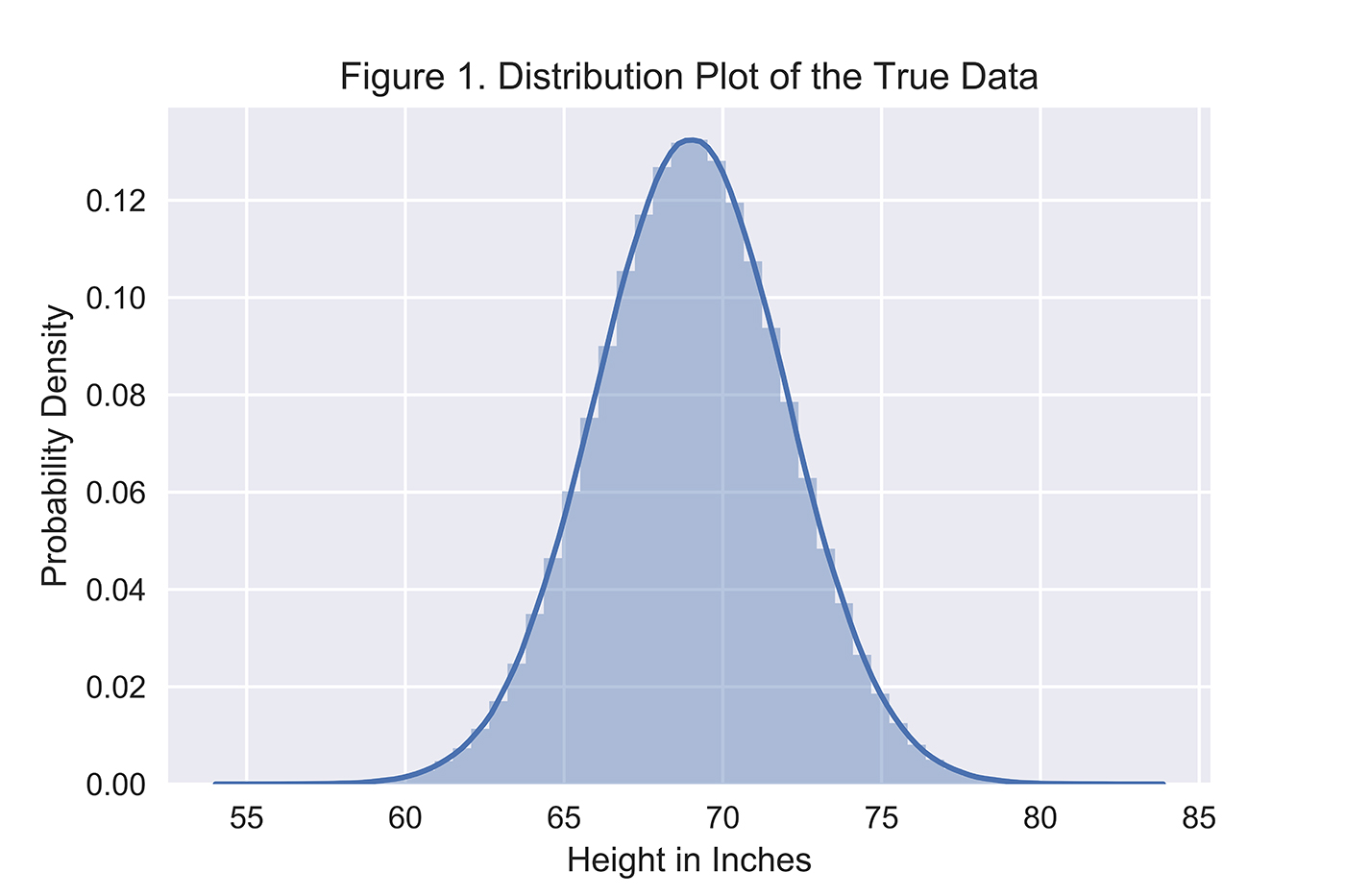
O gerador não conhece a verdadeira distribuição subjacente de alturas, mas tentará modelar essa distribuição com base em dados de altura reais que ela recebe. Quanto mais dados recebe, melhor será a sua distribuição modelo.n será. O gerador usará então esta distribuição do modelo para gerar alturas sintéticas, e o discriminador tentará identificar qual das alturas é real versus sintético.
Configurar as redes neurais
Para o gerador, usaremos uma rede neural com cinco camadas ocultas, cada uma com 10 nós ocultos. Em cada camada oculta, realizaremos uma transformação linear e passaremos por uma não-linearidade (função tangente hiperbólica). Para acelerar o treinamento, vamos realizar a normalização do lote , e, para resolver o excesso, usaremos o abandono escolar . Após a camada oculta final, realizaremos uma transformação linear final, deixando-nos com uma saída unidimensional.
Para o discriminador, usaremos uma rede neural com três camadas ocultas, cada uma com dois nós ocultos. Tal como acontece com o gerador, em cada camada oculta realizaremos uma transformação linear e passaremos por uma não-linearidade (função tangente hiperbólica). Dada a simplicidade desta rede neural, não realizaremos a normalização do lote ou o abandono do uso. Após a camada oculta final, realizaremos uma transformação linear final e passaremos pela função sigmoide, deixando-nos com uma saída unidimensional que pode ser interpretada como a confiança que o discriminador tem ao chamar uma falsificação.
Usando sua rede neural, o gerador G tentará mapear alturas reais – z 1 , z 2 , z 3 , …, z m , onde m é o número total de amostras – para x 1 , x 2 , x 3 , x 4 , …, x m tal que x i = G (z i ) . z i vem da distribuição de dados de altura verdadeira. x i são os dados sintéticos recém-gerados.
Se o gerador funcionar bem, a distribuição do modelo que ele gera será quase idêntica à verdadeira distribuição subjacente de alturas. Em outras palavras, X I será densa onde z i é densa, e X I vai ser escasso onde z i é escasso.
Defina as funções objetivas
O discriminador D receberá os dados de entrada x e determinará se o x pertence à distribuição de dados verdadeira. Se x é da distribuição de dados verdadeira, queremos que D (x) seja maximizado. Se x é sintético – a partir de agora referido como x ‘ , queremos que D (x’) seja minimizado.
A função objetivo para D é: log (D (x)) log (1 – D (x ‘)) , onde x é da distribuição de dados verdadeira (ie, z i ) e x’ é dados sintéticos x i gerados a partir de G (z i ) . O discriminador tentará maximizar essa função.
A função objetivo para G é: log (D (x ‘)) , onde x’ são dados sintéticos x i gerados a partir de G (z i ) . Quanto melhor o gerador é enganar o discriminador, maior será o valor dessa função.
Defina o otimizador e configure os hiperparâmetros
Nós usaremos um otimizador de descida gradiente simples para este problema com uma taxa de aprendizado inicial de 0,005. Esta taxa de aprendizado irá decair todas as 100 etapas que tomamos. Vamos usar um tamanho de lote de 200 e treinar por 10.000 épocas.
Comece a treinar e avaliar os resultados
Para avaliar os resultados, vamos traçar a verdadeira distribuição de dados e a distribuição de dados sintéticos juntamente com o limite de decisão do discriminador. Se o limite de decisão for igual ou próximo a 0,50, o discriminador não pode distinguir a diferença entre os dados reais e os dados sintéticos – apenas adivinha aleatoriamente neste ponto. Se o limite de decisão for muito maior ou inferior a 0,50, o discriminador é muito mais confiante ao pegar a falsificação.
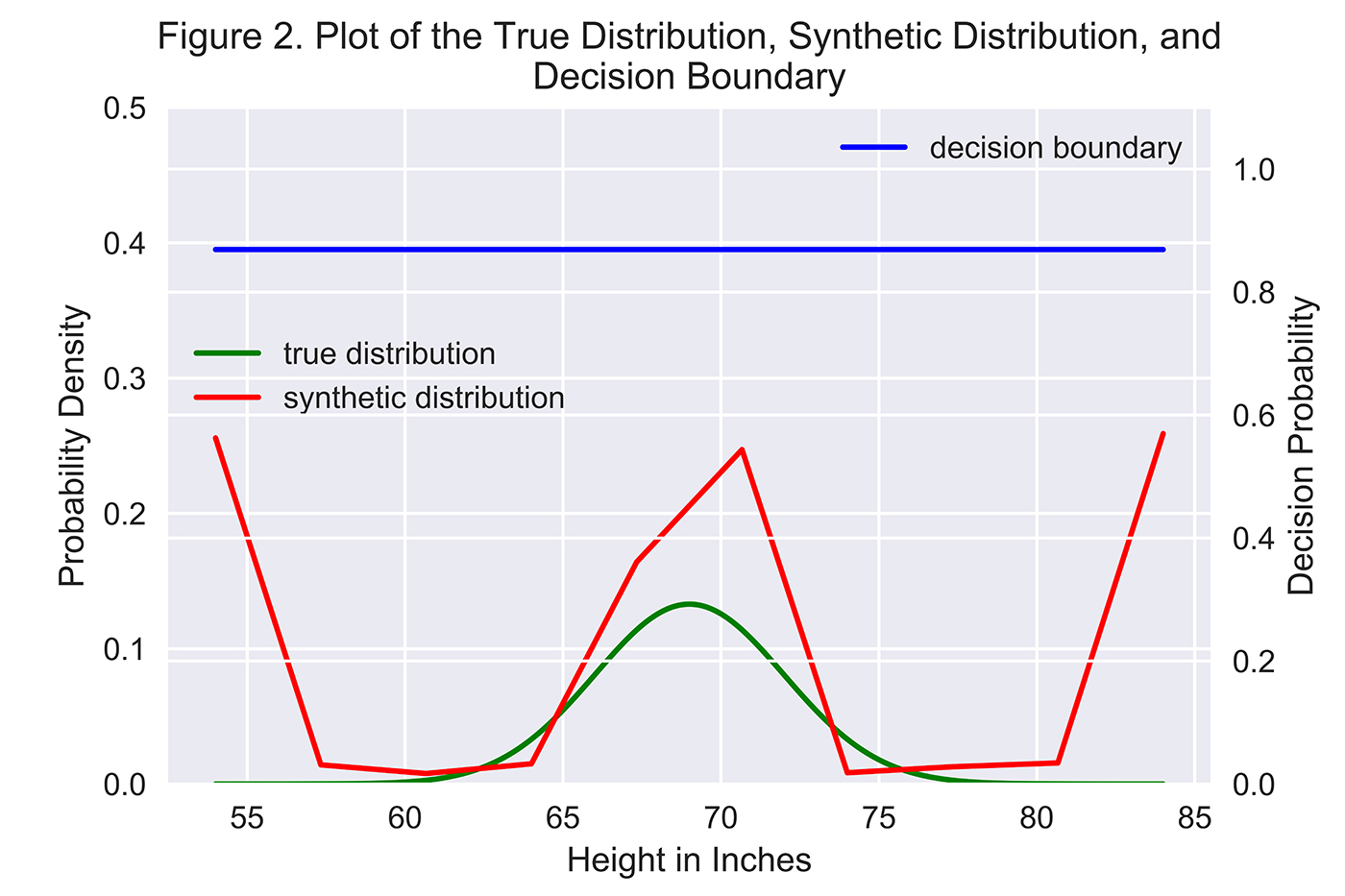
Na Figura 2, o limite de decisão (medido ema escala da direita) está acima de 0,80, o que significa que o discriminador é muito bom na identificação dos dados sintéticos. Mas, o gerador fica melhor ao longo do tempo – faz um bom trabalho para capturar onde o centro da distribuição se encontra, mas ainda luta com modelar as extremidades da cauda da verdadeira distribuição.
Neste exemplo simples, o gerador é bom, mas o discriminador é muito melhor. Para melhorar o gerador, podemos introduzir técnicas mais avançadas , incluindo a combinação de características e a discriminação de minibatch, ambas as quais exploraremos em um futuro artigo.
O poder eo potencial dos GANs
Em vez de modelar conjuntos simples de dados unidimensionais, podemos usar GANs para criar imagens e palavras sintéticas para complementar os conjuntos de dados reais existentes (por exemplo, para treinar modelos de aprendizado de máquina) ou, talvez para fins mais nefastos, criar documentos falsos e arte e personificar outras pessoas.
Também podemos usar GANs para realizar a detecção de anomalias usando o discriminador para detectar dados probabilisticamente raros (outliers) a partir de dados mais normais.
Ainda estamos nos estágios iniciais dos GANs , por isso muito trabalho permanece. Mas, com os GAN, os agentes de inteligência artificial podem gerar dados sintéticos que são praticamente indistinguíveis dos dados reais. Isto irá trazer AI um passo mais perto de passar o Turing Test , no qual ele exibe um comportamento que é quase idêntico ao de um humano – a Ex Machina e Westworld .
Em outras palavras, os GANs podem manter a chave para resolver uma das maiores façanhas no campo da inteligência artificial.
Contact Information:
Ankur Patel
Tags:
, Wire, Artificial Intelligence Newswire, United States, Portuguese
Keywords: afds, afdsafds
