








Aproveitando a Precisão e Quantização Baixas para Aprendizagem Profunda Usando o Amazon EC2 C5 Instance e BigDL

Recentemente, a AWS lançou as novas instâncias do Amazon EC2 C5 com uso intensivo de computação, com base nos processadores Intel Xeon Scalable Platinum de última geração. Essas instâncias são projetadas para aplicativos pesados em computação e oferecem uma grande melhoria de desempenho em relação às instâncias C4. Eles também possuem memória adicional por vCPU e duas vezes o desempenho para cargas de trabalho vetoriais e de ponto flutuante.
Neste blog, demonstraremos como o BigDL, uma estrutura de aprendizagem profunda distribuída de código aberto para o Apache Spark, pode aproveitar os novos recursos oferecidos nas instâncias do AWS C5 que podem melhorar significativamente as cargas de trabalho de grande profundidade em grande escala. Em particular, mostraremos como o BigDL pode aproveitar a baixa precisão e quantificação usando instâncias C5 para alcançar uma redução de 4x no tamanho do modelo e quase uma melhoria de 2x na velocidade de inferência.
Por que aprender profundamente em instâncias C5?
As novas instâncias do AWS C5 aproveitam os recursos do processador Intel Xeon Scalable, como maiores contagens de núcleo em freqüências de processador mais altas, memória de sistema rápida, cache grande de núcleo médio (cache MLC ou L2) e novas instruções SIMD largas (AVX -512). Esses recursos são projetados para impulsionar as operações de matemática envolvidas no aprendizado profundo, o que torna as novas instâncias C5 uma excelente plataforma para o aprendizado profundo em larga escala.
O BigDL é um framework de aprendizado profundo distribuído para o Apache Spark que foi desenvolvido e aberto pela Intel, e permite que os usuários criem e executem aplicativos de aprendizagem profunda em clusters Hadoop / Spark existentes. Desde a sua primeira fonte aberta em dezembro de 2016, a BigDL recebeu ampla adoção na indústria e na comunidade de desenvolvedores (por exemplo, Amazon, Microsoft , Cray, Alibaba , JD , MLSlistings e Gigaspace s, etc.).
O BigDL é otimizado para ser executado em grandes plataformas de dados de grande escala, que normalmente são construídas em cima de conjuntos de Hadoop / Spark baseados em Xeon distribuídos. Ele aproveita a Intel Math Kernel Library (MKL) e a computação multi-thread para alto desempenho e usa a estrutura Spark subjacente para uma escala eficiente. Conseqüentemente, ele pode aproveitar de forma eficiente os recursos disponíveis nas novas instâncias C5 da AWS, e observamos velocidades significativas em comparação com as gerações anteriores de famílias de instâncias.
Aproveitando a baixa precisão e quantificação
Além das melhorias de desempenho brutas obtidas com o uso de instâncias C5, a versão BigDL 0.3.0 também introduziu o suporte à quantificação do modelo, o que permite a inferência usando cálculos de precisão mais baixa. Correndo em instâncias C5 da AWS, vimos até uma redução de 4x no tamanho do modelo e quase uma melhoria de 2x na velocidade de inferência.
Qual é a quantização do modelo?
Quantização é um termo geral que se refere ao uso de tecnologias que armazenam números e realizam cálculos sobre eles de forma mais compacta e de menor precisão do que o formato original (por exemplo, ponto flutuante de 32 bits). O BigDL aproveita esse tipo de computação de baixa precisão para quantificar modelos pré-treinados para inferência: pode levar modelos existentes treinados em vários quadros (por exemplo, BigDL, Caffe, Torch ou TensorFlow), quantizam os parâmetros do modelo e os dados de entrada usando um formato de número inteiro mais compacto de 8 bits e, em seguida, aplique as instruções do vetor AVX-512 para cálculos rápidos de 8 bits.
Como a quantificação funciona no BigDL?
O BigDL permite que os usuários carregem diretamente modelos existentes treinados usando BigDL, Caffe, Torch ou TensorFlow. Depois que o modelo é carregado, o BigDL pode primeiro quantizar os parâmetros de algumas camadas selecionadas em um inteiro de 8 bits (usando a seguinte equação) para produzir um qModelo uantizado:
Durante a inferência do modelo, cada camada quantizada quantifica dinamicamente os dados de entrada em inteiro de 8 bits, aplica os cálculos de 8 bits (como o GEMM) usando os parâmetros e dados quantizados e desquantifica os resultados para o ponto flutuante de 32 bits. Muitas dessas operações podem ser fundidas na implementação e, conseqüentemente, as despesas gerais de quantificação e desquantidade são muito baixas no tempo de inferência.
Ao contrário de muitas implementações existentes, a BigDL usa um novo esquema de quantificação local para a quantificação do modelo. Ou seja, executa as operações de quantificação e desquantização (conforme descrito anteriormente) em cada pequena janela de quantificação local, um pequeno sub-bloco (como um patch ou kernel) dos parâmetros ou dados de entrada. Como resultado, o BigDL pode usar números inteiros de bits muito baixos, como 8 bits, na quantificação do modelo com queda de precisão do modelo extremamente baixa (menos de 0,1%) e pode alcançar algumas eficiências impressionantes, como mostrado nos gráficos a seguir com detalhes de a configuração de benchmark atual listada no final do blog.
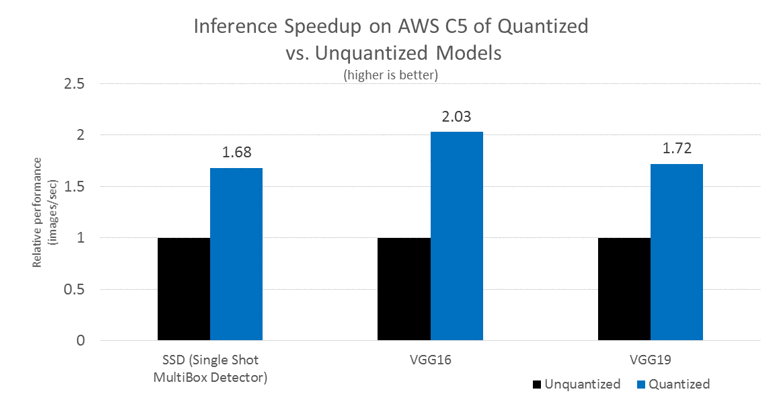
Aceleração de inferência em C5: desempenho relativo (modelos quantizados versus não descontados) – 1.69 ~ 2.04x aceleração de inferência usando quantização em BigDL
Precisão de inferência em C5: (Modelos quantificados versus não quantificados) – menos de 0,1% de queda de precisão usando quantização em BigDL

Tamanho do modelo (Modelos quantificados versus não quantificados) – ~ 3.9x redução do tamanho do modelo usando quantização no BigDL

Como usar a quantização no BigDL?
Para quantizar um modelo no BigDL, você primeiro carrega um modelo existente da seguinte maneira (consulte o documento BigDL para obter mais detalhes sobre o suporte Caffe e o suporte TensorFlow ):
Depois disso, você pode simplesmente quantizar o modelo e usá-lo para inferência da seguinte maneira:
Além disso, o BigDL também fornece ferramentas de linha de comando (ConvertModel) para converter o modelo pré-treinado em um modelo quantificado. Consulte o documento BigDL para obter mais detalhes sobre o suporte à quantização do modelo .
Experimente por si mesmo!
- Experimente o BigDL no AWS hoje através do Marketplace AWS .
- Você pode aprender mais sobre BigDL e quantificação do modelo aqui .
- Para executar o BigDL no Amazon EMR, você pode seguir as instruções em nossa postagem anterior do blog, Running BigDL, Deep Learning para Apache Spark, no AWS .
Detalhes da configuração do benchmark:
| Tipo de referência | Inferência |
| Métrica de referência | Imagens / Sec |
| Estrutura | BigDL |
| Topologia | SSD, VGG16, VGG19 |
| # de nós | 1 |
| Instâncias do Amazon EC2 | C5.18xlarge |
| tomadas | 2S |
| Processador | Geração “Skylake” |
| Núcleos habilitados | 36c (c5.18xlarge) |
| Memória total | 144 GB (c5.18xlarge) |
| Armazenamento | GP2 otimizado com EBS |
| SO | RHEL 7.4 3.10.0-693.el7.x86_64 |
| HT | EM |
| Turbo | EM |
| Tipo de computador | Servidor |
| Versão do framework | https://github.com/intel-analytics/BigDL |
| Conjunto de dados, versão | COCO, Pascal VOC, Imagenet-2012 |
| Comando de desempenho | Taxa de inferência medida em imagens / seg |
| Configuração de dados | Os dados foram armazenados no armazenamento local e armazenados em cache na memória antes do treinamento |
| Oracle Java | 1.8.0_111 |
| Apache Hadoop | 2.7.3 |
| Apache Spark | 2.1.1 |
| BigDL | 0.3.0 |
| Apache Maven | 3.3.9 |
| Protobuf | 2,5 |
Aviso de otimização: os compiladores da Intel podem ou não otimizar o mesmo grau para microprocessadores não-Intel para otimizações que não são exclusivas dos microprocessadores da Intel. Essas otimizações incluem conjuntos de instruções SSE2, SSE3 e SSSE3 e outras otimizações. A Intel não garante a disponibilidade, a funcionalidade ou a eficácia de qualquer otimização em microprocessadores não fabricados pela Intel. Otimizações dependentes do microprocessador neste produto destinam-se a serem usadas com microprocessadores da Intel. Algumas otimizações não específicas da microarquitetura Intel são reservadas para microprocessadores da Intel. Consulte o Produto aplicável aos Guias de Usuário e de Referência para obter mais informações sobre os conjuntos de instruções específicos abrangidos por este aviso.
Intel, o logotipo da Intel, Xeon, são marcas registradas da Intel Corporation nos EUA e / ou em outros países.
Contact Information:
Jason Dai and Joseph Spisak
Tags:
, Artificial Intelligence Newswire, Wire, United States, Portuguese
Keywords: afds, afdsafds
