








Construindo nossa própria versão do AlphaGo Zero – Rossum – Médio
Construindo nossa própria versão do AlphaGo Zero
Na Rossum , estamos construindo inteligência artificial para a compreensão dos documentos. Nossa principal linha de ataque reside na aprendizagem automática de máquinas , a abordagem mais eficiente para tornar as redes neurais alcançadas com a mais alta precisão. No entanto, precisamos de dados de treinamento muito detalhados nesta configuração, e é por isso que também estão buscando abordagens menos diretas, por exemplo, com base em redes de geração avançada ou aprendizagem de reforço avançado.
Minha história: de ir para redes neurais e reunião inesperada
Nos anos seguintes, concentrei meus esforços científicos no campo do reforço aprendendo-me, em particular na área de fazer o computador jogar o jogo de tabuleiro de Go . Fui cativado pelo jogo pouco antes, e foi considerado um dos desafios mais difíceis da AI de que poderíamos enfrentar com sucesso na época. 
Eu escrevi o então mais forte programa open source Pachi , e mais tarde acompanhei um programa educacional Michi (os algoritmos essenciais de estado de arte em 550 linhas de código Python). Alguns meses depois, o DeepMind da Google anunciou vários grandes avanços na aplicação de redes neurais ao jogo com o seu programa AlphaGo ; Enquanto isso, mudei para a pesquisa de rede neural na área de processamento de linguagem natural.
DeepMind agitou a comunidade de Inteligência Artificial novamente há apenas um mês, quando a equipe anunciou uma nova versão, o AlphaGo Zero – extraordinário devido ao fato de que desta vez, suas redes neurais foram capazes de aprender Ir completamente do zero sem conhecimento humano (treinamento supervisionado ou recursos feitos à mão), enquanto ele realmente exigia muito menos cálculos do que antes.
“Dominando o jogo de Go sem conhecimento humano”
Um longo objetivo da inteligência artificial é um algoritmo que aprende, tabula rasa , proficiência sobre-humana em domínios desafiadores. Recentemente, o AlphaGo tornou-se o primeiro programa a derrotar um campeão mundial no jogo de Go. (…) Começando a tabula rasa , o nosso novo programa AlphaGo Zero alcançou desempenho sobre-humano, ganhando 100-0 contra o AlphaGo, que já foi publicado anteriormente.
eu liZAUMnRQ” target = “_ blank” rel = “nofollow noopener” data-href = “https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ”> artigo da Nature o mesmo À noite, foi publicado e fiquei entusiasmado! Combinando a experiência do meu Computador e depois trabalhando em redes neurais, pareceu que não demoraria muito para recuperar o princípio do AlphaGo Zero – a base do algoritmo era muito mais simples do que a AlphaGo original, uma rede única e elegante treinada em um loop sem heurísticas extras para se preocupar.
Bem, quando eu fui dormir às 5h na mesma noite, a primeira versão de um novo programa do Go, Nochi, estava triturando jogos no cluster GPU de Rossum.
História de DeepMind: de AlphaGo para AlphaGo Zero
A base do AlphaGo Zero é simples: uma única rede neural que simultaneamente avalia posições e sugere movimentos de acompanhamento para explorar e o clássico algoritmo Monte Carlo Tree Search para construir a árvore de movimento do jogo, explorar acompanhamentos e encontrar contadores de movimentos – apenas neste caso, ele usa apenas a rede neural ao invés de jogar muitas simulações de jogos aleatórios (o que foi o caso de todos os programas Go Go anteriores).
Em seguida, comece com uma rede neural completamente aleatória que prevê apenas um caos puro e jogue muitos jogos contra si mesmo em um loop, uma e outra vez. A rede neural é treinada com base em quais situações previu corretamente e quando adivinhou errado: uma política de aprendizado de reforço é construída. Ao longo do tempo, a ordem emerge do caos e o programa é melhor por cada hora gasto no cluster TPU do Google.
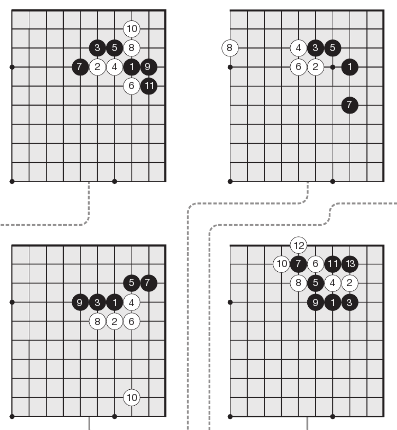
É bastante surpreendente que aprender a jogar Go de “os primeiros princípios” ao nível super-humano foi realmente muito mais rápido do que o chamado AlphaGo original. Também é surpreendente que as estratégias descobertas sejam realmente muito parecidas com o que os seres humanos desenvolveram ao longo de milhares de anos – nós estávamos no caminho certo!
Ao ver como o AlphaGo se compara com o AlphaGo Zero, é fácil identificar três avanços principais que contribuíram para AlphaGo Zero:
- Não baseando o treinamento em registros de jogos de jogos humanos.
- Uma única rede neural simples que substitui o bloqueio complexo de duas redes neurais usadas no AlphaGo original.
- Unidades residuais (parecidas com ResNet ) na rede neural convolucional que é usada para a avaliação da placa Go.
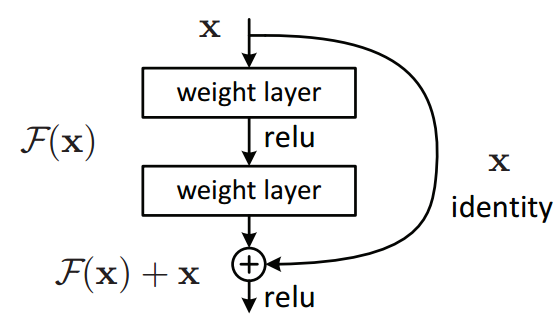
O último ponto desenha uma recomendação geral: se você estiver usando redes neurais convolutivas pré-ResNet para tarefas visuais, considere atualizar se a precisão é importante! Na Rossum, temos consistentemente visto um aumento na precisão em todas as tarefas onde fizemos isso, o mesmo o AlphaGo time descoberto.
Rossum’s Go Program: Nochi
Meu pequeno programa Python Michi continha uma implementação das regras Go, o algoritmo Monte Carlo Tree Search e simulações de jogos randomizados usados para a avaliação. Isso foi ideal – basta apenas substituir as simulações de jogos randomizados por uma rede neural baseada em Keras e adicionar um ciclo de treinamento “auto-play” ao programa. E assim nasceu Nochi. (Claro que, embora tenha demorado uma noite para implementá-lo, não quer dizer que não estivemos debugando e apertando as próximas semanas …) 
Mas há uma captura. O AlphaGo Zero é muito menos exigente que o antigo Alphago, mas executar a mesma configuração ainda levaria 1700 GPU-ano com hardware comum. (Pense sobre as capacidades computacionais do Google e o que eles conseguiram com suas Unidades de processamento de Tensor por um momento!)
Portanto, fizemos a instalação mais fácil para nós – em vez da placa 19×19 em grande escala, treinamos o Nochi apenas em 7×7, o menor painel sensível. Nós também fizemos ajustes na abordagem original – uma arquitetura de rede neural ligeiramente diferente baseada em nossa experiência com o que funciona melhor no Rossum e um currículo de treinamento muito mais agressivo que garante que nenhuma posição vista durante os jogos auto-jogados seja desperdiçada e a A rede neural converge o mais rápido possível.
Esta é a configuração onde o Nochi foi a primeira replicação do AlphaGo Zero que alcançou o nível da linha de base do GNU Go . (GNU Go é um programa clássico de nível intermediário que é popular para compararmos outros algoritmos). Além disso, o nível de Nochi melhora com o tempo alocado por movimento, o que sugere que a rede neural não apenas memorizou jogos, mas aprendeu a generalizar e descobrir táticas abstratas e estratégia. E a melhor parte? Nochi é de código aberto no GitHub , e ainda é um pequeno programa Python que qualquer um pode aprender.
Vários outros esforços para replicar o sucesso do AlphaGo Zero estão em andamento – por exemplo, Leela Zero e Odin Zero . Afinal, o mundo ainda precisa de um super-humano Go playing software que qualquer um pode instalar e aprender! Mas vamos rootear do banco de dados – nossa atenção completa novamente pertence aos documentos e nossa visão de eliminar toda a entrada manual de dados do mundo.
See Campaign: http://medium.com/rossum/building-our-own-version-of-alphago-zero-b918642bd2b5
Contact Information:
Petr Baudis
Tags:
, Wire, Artificial Intelligence Newswire, United States, Portuguese
Keywords: afds, afdsafds
